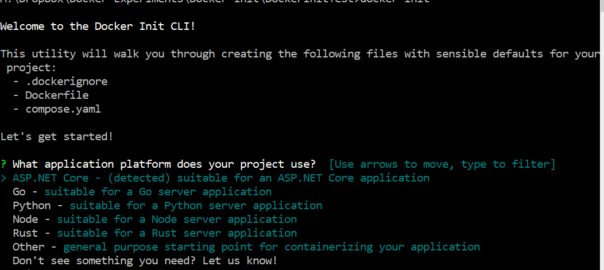
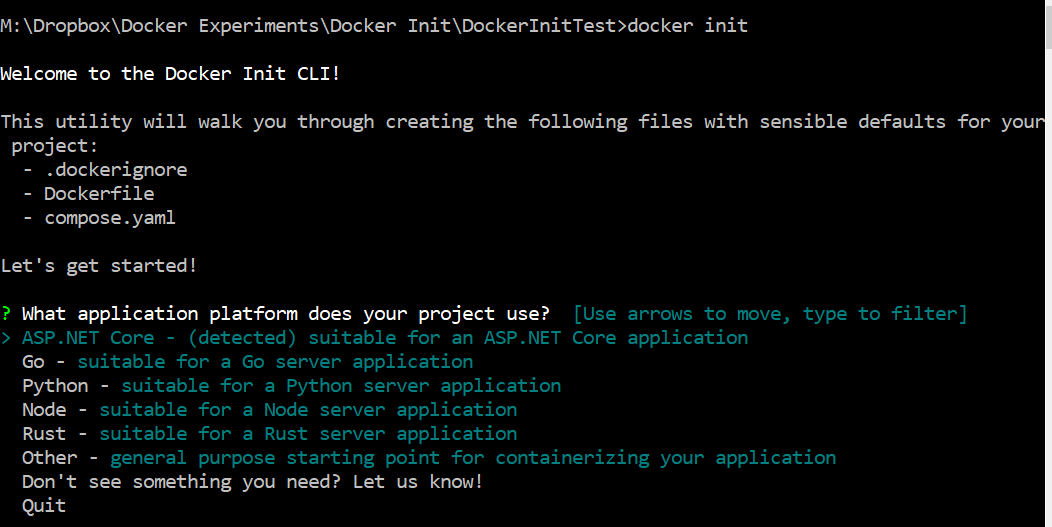
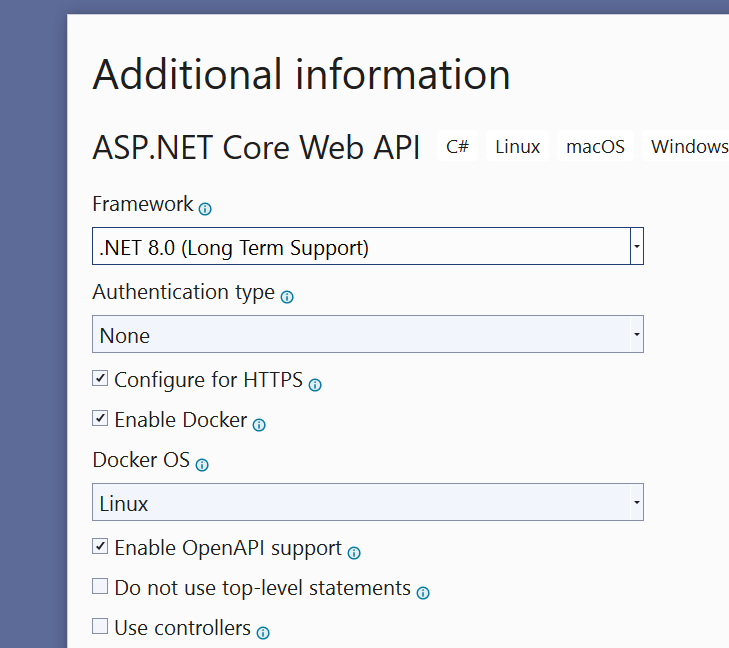
Docker’s compose watch feature was first released in Sept 2023 as part of docker compose v 2.22.0 (https://docs.docker.com/compose/release-notes/#2220)
Here are some tips and behaviors to be aware of when using compose watch in Visual Studio Code as well as how they relate to compose up.
While it shouldn’t make a difference, note that I’m using MacOS Monterey, latest VS Code (1.90.2) and latest (official Microsoft) Docker extension for VS Code (v1.29.1).
My app is a tiny dotnet web app using a minimal API. I’ve also performed the same experiments using a more complex app (with a database and FlywayDB containers and using controllers instead of minimal API). In the minimal API, one of the mapgets is defined in the program.cs file, the other is in a endpoints file and connected using a method to add those to the API. I did this to see if that made a difference in recompiling. More on that further on.
With a combination of “instructions” in your docker-compose file and the watch command, Docker will keep an eye out for code changes in the relevant container(s) that you have specified for watching , then update and rebuild the container on-the-fly. It’s an incredible improvement over having to explicitly take down the container (whether you stop or remove) then spin it up again to try out the changes. And thanks to the efficient caching in docker compose (the v2 compose, not the older docker-compose command) it can do so very quickly. Sounds magical, right?
Container updates? What?
How do I know the container with my app got updated? Two ways. The docker terminal in VS Code outputs all of the rebuild details and I leave the web page open after calling my API Get the first time and refresh the page after the container is rebuilt to see the new response data.
The Repo
The solution I’m using for testing can be found at https://github.com/julielerman/DockerComposeWatchDemoMinimalAPI.
Setting up docker-compose for watching
The key in the docker-compose file is a service subsection called watch inside the develop section for whichever service (container) you want to be watched. Below is a simple example.
I want watch to update the valuesapi container if I change any of the API code. I’ve added a minimal develop section in my docker-compose.yml file to support that in the API service. You can learn more about the various attributes in the develop specification doc (https://docs.docker.com/compose/compose-file/develop).
develop:
watch:
- action: rebuild
path: .
Here is the full compose file so you can see where this section sits within the service.
services: valuesapi: image: ${DOCKER_REGISTRY-} build: context: . dockerfile: Dockerfile ports: - 5114:5114 develop: watch: - action: rebuild path: .
Lesson Number One: Control Autosave Settings
I have always had autosave enabled with the “afterDelay” option in Visual Studio Code. And I’ve just allowed the default timing afterDelay at 1000 milliseconds. I quickly learned that AutoSave was a big problem as I was working on some edits and Docker kept updating the container over and over again as I was typing and thinking. Not a favorable situation.
The other options are
- onFocusChange (when the editor loses focus)
- onWindowChange (when the window loses focus)
- off
I initially just completely disabled AutoSave with off, but that is also dangerous since I’m so used to relying on it. Instead I changed the setting to onFocusChange which seemed most reasonable to me. I still find myself needing to explicitly save but expect I’ll get used to it.
How Quickly is the Container Updated?
Before I discuss the docker compose syntax, I do want to give you a sense of how quickly Docker updates a container.
I’m only using the docker compose watch command for the tests in this section.
Obviously, everyone’s performance will be different with respect to their setup so YMMV. But the results should be relative.
To begin with, calling docker compose watch takes no more time than docker compose up.
Keep in mind that a change to my dotnet web app means that dotnet needs to rebuild the app. If it’s just code, that’s simple.
I noticed that the first change I made that triggered Docker to recreate the build and publish image layers.
=> [valuesaapi build 7/7] RUN dotnet build "ValuesTest.csproj" 11.0s => [valuesaapi publish 1/1] RUN dotnet publish "ValuesTest.cspro 3.4s
The entire rebuild was 15.2 seconds before the API reflected the change.
Yet on subsequent changes, the rebuild was only 0.5 seconds and those two layers came from the cache.
=> CACHED [valuesaapi build 7/7] RUN dotnet build "ValuesTest.cs 0.0s => CACHED [valuesaapi publish 1/1] RUN dotnet publish "ValuesTes 0.0s
I have no idea how this is working (how the change is getting to the container layer) because the change was, indeed, reflected in the output from the API. I can’t explain this difference but will be asking about it for sure! (Then will come back to edit this post.)
Here is a look at the docker log for the rebuild of the version of the app, where you can see how it reuses most of the cached layers. This was the first rebuild which spent more time on those two layers noted above.
Rebuilding service "valuesaapi" after changes were detected... [+] Building 15.2s (20/20) FINISHED docker:default => [valuesaapi internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 1.25kB 0.0s => [valuesaapi internal] load metadata for mcr.microsoft.com/dot 0.3s => [valuesaapi internal] load metadata for mcr.microsoft.com/dot 0.2s => [valuesaapi internal] load .dockerignore 0.0s => => transferring context: 383B 0.0s => [valuesaapi build 1/7] FROM mcr.microsoft.com/dotnet/sdk:8.0- 0.0s => [valuesaapi internal] load build context 0.0s => => transferring context: 1.74kB 0.0s => [valuesaapi base 1/4] FROM mcr.microsoft.com/dotnet/aspnet:8. 0.0s => CACHED [valuesaapi build 2/7] WORKDIR /src 0.0s => CACHED [valuesaapi build 3/7] COPY [API/ValuesTest.csproj, AP 0.0s => CACHED [valuesaapi build 4/7] RUN dotnet restore "API/ValuesT 0.0s => [valuesaapi build 5/7] COPY . . 0.1s => [valuesaapi build 6/7] WORKDIR /src/API 0.1s => [valuesaapi build 7/7] RUN dotnet build "ValuesTest.csproj" 11.0s => [valuesaapi publish 1/1] RUN dotnet publish "ValuesTest.cspro 3.4s => CACHED [valuesaapi base 2/4] WORKDIR /app 0.0s => CACHED [valuesaapi base 3/4] RUN apk add --no-cache icu-libs 0.0s => CACHED [valuesaapi base 4/4] RUN adduser -u 5678 --disabled-p 0.0s => CACHED [valuesaapi final 1/2] WORKDIR /app 0.0s => [valuesaapi final 2/2] COPY --from=publish /app/publish . 0.1s => [valuesaapi] exporting to image 0.1s => => exporting layers 0.1s => => writing image sha256:454f1258e665324777310e3df67674407b73e 0.0s => => naming to docker.io/library/api 0.0s service "valuesaapi" successfully built
Also note that the pre-existence of the container may not be relevant. It is all about the build cache. So you may remove the container then run compose watch again and it will spin up very quickly. There are so many factors at play that as many times as you experiment, you may realize slightly different behavior. I have played with this many many times in order to come to a decent comprehension of what is going on (though not quite “how” …I’ll just chalk that up to Docker developer genius for now.)
But what if I do something like introduce a new package in my csproj file? (I’ll let you translate that question to the facets of your chosen coding stack.)
Adding a new Nuget package to the API’s csproj was, as expected, more expensive at about 50 seconds total. Here is the output from that change. Looking at the timing for each step, the bulk was restoring the newly added Nuget package over my SLOW internet! I could have run dotnet restore in advance, of course. Then it also required a rebuild of the project that could not rely on the cache. That was over 13 seconds and another 3.7 to create the publish image.
Rebuilding service "valuesaapi" after changes were detected... [+] Building 51.5s (20/20) FINISHED docker:default => [valuesaapi internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 1.25kB 0.0s => [valuesaapi internal] load metadata for mcr.microsoft.com/dot 0.5s => [valuesaapi internal] load metadata for mcr.microsoft.com/dot 0.5s => [valuesaapi internal] load .dockerignore 0.0s => => transferring context: 383B 0.0s => [valuesaapi build 1/7] FROM mcr.microsoft.com/dotnet/sdk:8.0- 0.0s => [valuesaapi base 1/4] FROM mcr.microsoft.com/dotnet/aspnet:8. 0.0s => [valuesaapi internal] load build context 0.0s => => transferring context: 1.47kB 0.0s => CACHED [valuesaapi build 2/7] WORKDIR /src 0.0s => [valuesaapi build 3/7] COPY [API/ValuesTest.csproj, API/] 0.0s => [valuesaapi build 4/7] RUN dotnet restore "API/ValuesTest.cs 32.8s => [valuesaapi build 5/7] COPY . . 0.1s => [valuesaapi build 6/7] WORKDIR /src/API 0.0s => [valuesaapi build 7/7] RUN dotnet build "ValuesTest.csproj" 13.5s => [valuesaapi publish 1/1] RUN dotnet publish "ValuesTest.cspro 3.7s => CACHED [valuesaapi base 2/4] WORKDIR /app 0.0s => CACHED [valuesaapi base 3/4] RUN apk add --no-cache icu-libs 0.0s => CACHED [valuesaapi base 4/4] RUN adduser -u 5678 --disabled-p 0.0s => CACHED [valuesaapi final 1/2] WORKDIR /app 0.0s => [valuesaapi final 2/2] COPY --from=publish /app/publish . 0.2s => [valuesaapi] exporting to image 0.3s => => exporting layers 0.3s => => writing image sha256:a5f16fef8705421b73499f2393cf7e790b958 0.0s => => naming to docker.io/library/api 0.0s service "valuesaapi" successfully built
Removing the Nuget package forced another expensive restore:
=> [valuesaapi build 4/7] RUN dotnet restore "API/ValuesTest.cs 10.0s
And re-building the layered images took about the same time as before.
=> [valuesaapi build 7/7] RUN dotnet build "ValuesTest.csproj" 11.1s => [valuesaapi publish 1/1] RUN dotnet publish "ValuesTest.cspro 3.4s
Lesson Number 2, compose syntax impacts your experience
With the develop/watch section in place in docker-compose, you can then trigger the watch with docker compose in two ways:
docker compose watch or
docker compose up –watch.
But the two ways have different effects and it took me some experimenting to understand the effects. Below I will lay out the various syntaxes for comparison so that you can avoid some of the confusion I encountered as I was learning.
compose up variations
docker compose up
If you run docker compose up without the –watch flag, the Docker extension will give you the option to watch the source with the w key. If you do that, code changes trigger rebuild and you’ll get an updated API.

The CLI terminal (in my case, zsh) gets replaced with a docker terminal.
All info goes to this terminal including output debug / log info from dotnet.
If you enabled watch, then the rebuild details (as above) will also be displayed in this terminal window.
CTRL-C stops the containers, closes the docker terminal, returns to zsh terminal and prompt. Containers are still there, just stopped, not running.
If you want to remove the containers, you’ll have to use docker compose down command or by right clicking the container in the docker extension explorer and choosing remove or right clicking the docker-compose file in the explorer and choosing compose down.
docker compose up -d or docker compose up -d watch
If you want Docker to watch, this is not your friend!
Running compose up in interactive mode, that is with the -d (detached) flag, will never work with watch. It won’t activate because Docker releases control back to you and therefore is not able to keep an eye on code changes. If you don’t add the –watch attribute, you will not get the prompt to start watch with the “w” key. If you do add the –watch attribute, watch will simply not activate. But there is no warning and was confused until I realized what was going on. Having learned this the hard way, I hope this will help you avoid the same confusion.
Another detriment to interactive/detached mode with or without the watch is that dotnet debug/log output is not displayed in the terminal. Or in any of the windows. You’ll have to force it to another target in your code.
Why so much focus on detached mode? In the Docker extension, if you right click a compose file and choose compose up from the extension’s context menu, the default command executed includes the -d. You can override those commands in the settings if you want.
In order to stop/remove containers ,you need to use the CLI or the tooling to trigger the CLI command e.g. docker compose down. CTRL-C will not have any effect.
Using compose watch command instead of compose up command
docker compose watch
Note there isn’t even a detached option available with watch because it’s totally irrelevant.
The terminal will tell you that watch is enabled when compose is finished spinning up the containers. As we are not interactive, you will not be released to a terminal prompt. Logs and message from the app will display in the Docker terminal as well as notifications from Docker. Code changes trigger rebuild (visible in terminal) and the app gets updated.
CTRL-C closes the Docker terminal and brings you back to a prompt and Docker stops watching. The containers are still running, however. But if you make code changes, they will not be updated because watch was no longer active. Now that the Docker terminal is gone, dotnet logs and other message coming from within the container are NOT output anywhere.
In this state (containers running, watch disabled, docker terminal gone and a recent change made to the code) I ran docker compose watch again from the prompt. Even though the containers were still running, keep in mind that the code change I made wasn’t handled. So the dotnet app had to be rebuilt and the API container updated. The dotnet build command took about 15 seconds and the entire composition was about 20 seconds.
Don’t Overlook compose watch!
After 30+ years coding, I still always tend to fear change in my tools .. worried that it will make me confused and feel stupid. (It usually does for a few minutes ..or perhaps longer…but then you figure it out It and feel like a million bucks!). It took me a long time before I looked at compose watch (with some encouragement) and in my typical fashion I had to try out what happens if I do this? what happens if I do that? until I had a good idea of how its works and how incredibly useful it is! Don’t be shy…. it is an incredibly useful feature if you are developing with Docker.
 I spent much of the fall and winter updating my three EF Core courses.
I spent much of the fall and winter updating my three EF Core courses.